
Votre panier est vide.
Certains articles de veille peuvent faire l'objet de traduction automatique.
Les réseaux antagonistes génératifs (GAN) ont été accueillis avec un réel enthousiasme depuis leur création en 2014 par Ian Goodfellow et son équipe de recherche. Yann LeCun, directeur de Facebook de IA La recherche est allée jusqu’à décrire les GAN comme «l’idée la plus intéressante des 10 dernières années en ML». Avec toute cette excitation, cependant, il peut être facile de passer à côté de la subtile diversité des GAN; il existe un certain nombre de types différents de réseaux antagonistes génératifs, chacun fonctionnant de manière légèrement différente et aidant les ingénieurs à obtenir des résultats légèrement différents.
Pour vous donner un aperçu plus approfondi des GAN, dans cet article, nous examinerons trois différents réseaux antagonistes génératifs: les SRGAN, les CycleGAN et les InfoGAN. Nous allons explorer comment ces différents GAN fonctionnent et comment ils peuvent être utilisés. Cela devrait vous donner une base solide pour explorer plus en profondeur les GAN et commencer à les appliquer dans vos propres expériences et projets.
 Cet article est un extrait du livre, Apprentissage profond avec TensorFlow 2 et Keras, deuxième édition par Antonio Gulli, Amita Kapoor et Sujit Pal.
Cet article est un extrait du livre, Apprentissage profond avec TensorFlow 2 et Keras, deuxième édition par Antonio Gulli, Amita Kapoor et Sujit Pal.
SRGAN – GAN super résolution
Vous vous souvenez avoir vu un thriller policier où notre héros demande au gars de l’informatique d’agrandir l’image fanée de la scène du crime? Avec le zoom, nous pouvons voir le visage du criminel en détail, y compris l’arme utilisée et tout ce qui est gravé dessus! Eh bien, SRGAN peut effectuer une magie similaire.

Ici, un GAN est formé de telle manière qu’il peut générer une image photoréaliste haute résolution lorsqu’il est donné une image basse résolution. L’architecture SRGAN se compose de trois réseaux neuronaux: un réseau de générateurs très profond, un réseau discriminateur et un réseau VGG-16 pré-entraîné.
Comment fonctionnent les SRGAN?
Les SRGAN utilisent la fonction de perte perceptive (développée par Johnson et al, Perceptual Losses for Real-Time Style Transfer and Super-Resolution). La différence dans les activations de la carte de caractéristiques dans les couches hautes d’un réseau VGG entre la partie de sortie du réseau et la partie haute résolution comprend la fonction de perte de perception. Outre la perte de perception, les auteurs ont ajouté une perte de contenu et une perte contradictoire afin que les images générées paraissent plus naturelles et les détails plus fins plus artistiques. La perte de perception est définie comme la somme pondérée de la perte de contenu et de la perte contradictoire:
lSR = lSR X + 10−3 × lSRGen
Le premier terme à droite est la perte de contenu, obtenue à l’aide des cartes de caractéristiques générées par VGG 19 pré-entraîné. Mathématiquement, c’est la distance euclidienne entre la carte de caractéristiques de l’image reconstruite (c’est-à-dire celle générée par le générateur) et l’image de référence haute résolution d’origine.
Le deuxième terme du côté droit est la perte contradictoire. C’est le terme standard de perte générative, conçu pour garantir que les images générées par le générateur sont capables de tromper le discriminateur. Vous pouvez voir sur la figure suivante tirée du papier d’origine que l’image générée par SRGAN est beaucoup plus proche de l’image haute résolution d’origine:

CycleGAN
Une autre architecture remarquable est CycleGAN; proposé en 2017, il peut effectuer la tâche de traduction d’images. Une fois formé, vous pouvez traduire une image d’un domaine vers un autre domaine. Par exemple, lorsqu’il est entraîné sur un jeu de données de chevaux et de zèbres, si vous lui donnez une image avec des chevaux dans le sol, le CycleGAN peut convertir les chevaux en zèbre avec le même arrière-plan.
Comment fonctionne CycleGAN?
Avez-vous déjà imaginé à quoi ressemblerait un paysage si Van Gogh ou Manet l’avait peint? Nous avons de nombreux paysages et de nombreux paysages peints par Gogh / Manet, mais nous n’avons aucune collection de paires d’entrée-sortie. CycleGAN effectue la traduction d’image, c’est-à-dire transfère une image donnée dans un domaine (décor par exemple) vers un autre domaine (peinture de Van Gogh de la même scène, par exemple) en l’absence d’exemples d’apprentissage. La capacité de CycleGAN à effectuer la traduction d’images en l’absence de paires de formation est ce qui le rend unique.
Pour réaliser la traduction d’images, les auteurs de CycleGAN ont utilisé une procédure très simple et pourtant efficace. Ils ont utilisé deux GAN, le générateur de chaque GAN effectuant la traduction d’image d’un domaine à un autre.
Pour élaborer, disons que l’entrée est X, puis le générateur du premier GAN effectue un mapping G: X → Y, ainsi sa sortie serait Y = G (X). Le générateur du deuxième GAN effectue une cartographie inverse F: Y → X, résultant en X = F (Y). Chaque discriminateur est formé pour faire la distinction entre les images réelles et les images synthétisées. L’idée se présente comme suit:
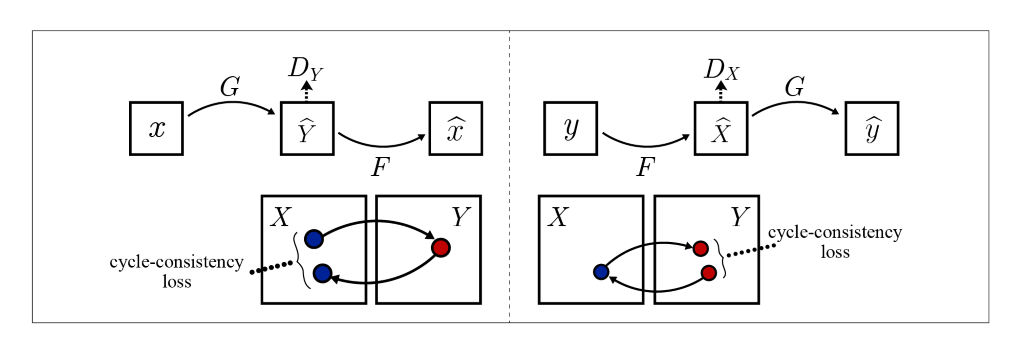
Pour former les GAN combinés, les auteurs ont ajouté à côté de la perte antagoniste GAN conventionnelle une perte de cohérence du cycle avant (figure de gauche) et une perte de cohérence du cycle en arrière (figure de droite). Cela garantit que si une image X est donné en entrée, puis après les deux traductions F (G (X)) ~ X l’image obtenue est la même X (de même, la perte de cohérence du cycle en arrière assure la G (F (Y)) ~ Y).
Voici quelques-unes des traductions d’images réussies par CycleGAN:

Voici quelques exemples supplémentaires, vous pouvez voir la traduction des saisons (été → hiver), photo → peinture et vice versa, chevaux → zèbre:

InfoGAN
Les architectures GAN que nous avons envisagées jusqu’à présent nous offrent peu ou pas de contrôle sur les images générées. InfoGAN change cela; il permet de contrôler divers attributs des images générées. L’InfoGAN utilise des concepts de la théorie de l’information tels que le terme de bruit est transformé en codes latents qui fournissent un contrôle prévisible et systématique sur la sortie.
Comment fonctionne InfoGAN?
Le générateur dans InfoGAN prend deux entrées l’espace latent Z et un code latent c, ainsi la sortie du générateur est G (Z, c). Le GAN est formé de telle sorte qu’il maximise les informations mutuelles entre le code latent c et l’image générée G (Z, c). La figure suivante montre l’architecture d’InfoGAN:
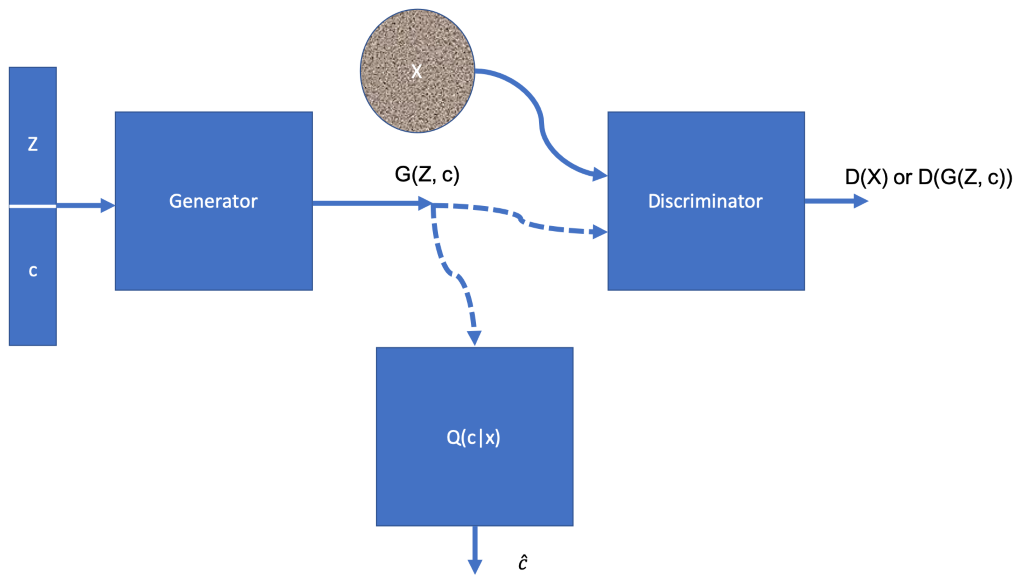
Le vecteur concaténé (Z, c) est acheminé vers le générateur. Q (c | X) est aussi un réseau de neurones, combiné avec le générateur il fonctionne pour former une cartographie entre le bruit aléatoire Z et son code latent bavarder, il vise à estimer c donné X. Ceci est réalisé en ajoutant un terme de régularisation à la fonction objective du GAN conventionnel:
minDmaxG VI (D, G) = VG (D, G) −λI (c; G (Z, c))
Le terme VG (D, G) est la fonction de perte du GAN conventionnel, et le deuxième terme est le terme de régularisation, où λ est une constante. Sa valeur a été fixée à 1 dans l’article, et I (c; G (Z, c)) est l’information mutuelle entre le code latent c et l’image générée par le générateur G (Z, c).
Voir aussi :



Poster un commentaire